Interesting blog posts back and forth between Don Rubin,
Judea Pearl, and Andrew Gelman. I cannot understand the original point of contention between Don Rubin and Judea Pearl. I have no idea what "M-bias", "controlling for pre-treatment versus post-treatment variables" mean.
http://www.stat.columbia.edu/~cook/movabletype/archives/2009/07/disputes_about.html
 Image via Wikipedia
Image via Wikipedia
Happily, the fundamental point of disagreement seems to be getting clear with a
comment by
Philip Dawid (who offers a very nice on-line document "
Principles of Statistical Causality" which covers a lot of concepts in only 94 pages). This is a very clear summary of what is meant by "causal inference":
Like Pearl, I like to think of "causal inference" as the task of inferring what would happen under a hypothetical intervention, say F_E = e, that sets the value of the exposure E at e, when the data available are collected, not under the target "interventional regime", but under some different "observational regime". We could code this regime as F_E = idle.
...
It should be obvious that, even to begin to think about the task of using data collected under one regime to infer about the properties of another, we need to make (and should attempt to justify!) assumptions as to how the regimes are related.
(Emphasis on the turn of phase that caught Andrew Gelman's eye)
What is the nature of the discipline of "statistical causal modeling"? Beats me.
I have the idea of
several DAGs (gaps filled in with plausible causal contributors),
several multi-dimensional collected sample distributions (gaps filled in with smoothing or naive-Bayesian techniques),
several simulations based on plausible natural or un-natural laws (simulations providing multi-dimensional distributions). Between creatures of all three types, we test them against historical data, future data, and intervention experiments. They fight against themselves, and only a few remain.
I have the idea of defining a distribution as the opportunity to open a sample portal to an alternate universe to the same sample stream. You can open sample portals at a certain rate, so the total number of samples available to you has a rate that increases as the square of time.

You desire the sample portals to all have the same correct driving distribution.
Now, obviously, you cannot actually create sample portals to alternate universes. So you create more fake sample portals. Each has the possibility of one or more failure modes.
Taken all together, these form a pessimistic analysis. Human action is inherently optimistic, so, take the opportunity to make
explicit biases of personality and human real-world population studies of life outcomes consistent with living a happy and fulfilled life. The third leg of the stool is a model of human effectiveness:
- rationality,
- choice,
- free will,
- changes in capability,
- changes in habitual action,
- goal-directed action,
- effectiveness,
- consciousness,
- self-knowledge/introspection,
- knowledge of the world,
- consistency between behavior and professed mental abstractions of desired behavior,
- and morality -
leading to the outcome of a happy and fulfilled life.
That is what I got right now.
The way to study how "human action is inherently optimistic" is with happiness research (covered in Daniel Gilbert's
Stumbling On Happiness, and the sections on happy outcomes in
Dan Ariely's
Predictably Irrational).
The model of human effectiveness is based on there being only a few chances over time for exercising free-will.
We greatly limit the role of free-will, because human behavior is better explained by:
- habitual actions,
- personality,
- IQ,
- daily exercised capability,
- daily exercised responses,
- environment,
- etc.
We expect to see meaningful change caused by free-will events over the course of 10 years - just because there are so few meaningful free-will events during those many years.
 Image via Wikipedia
Image via Wikipedia
Like
Julian Jaynes arguing in
The Origin of Consciousness in the Breakdown of the Bicameral Mind that consciousness only came into existence 3000 years ago from stresses on growing populations searching and competing for sustaining resources, I don't think that free-will is a capability of all humans since
Homo sapiens originated 200,000 years ago. I think meaningful free-will also is a recent phenomenon. And I don't think it is expressed in all people - it only gets exercised under a peculiar stress of personality and environment, when the capability exists.
I reject the idea that free-will is simply random behavior, or the absence of a mechanism for the deterministic prediction of behavior.
It cannot be meaningfully separated from these: rationality, goal-directed action, effectiveness, consciousness, self-knowledge/introspection, consistency between behavior and professed mental abstractions of desired behavior, morality, and other issues.
The reason for the need to consider time periods on the scale of a decade is that free-will events are the residue of actions and behaviors that cannot be explained by simpler means. Because it is a residue, we are only interested if there is a over-riding consistency and progression - because we don't want to give the label of "free-will" to an odd-ball collection of junk.
That's enough for now.
Added: Andrew Gelman explores issues further:
More on Pearl's and Rubin's frameworks for causal inference
He describes the idea of using Minimal Rubin, Full Rubin, Minimal Pearl, Full Pearl as techniques for statistical causality. And this note on the benefit of Rubin's approach:
Be explicit about data collection. For example, if you're interested in the effect of inflation on unemployment, don't just talk about using inflation as a treatment; instead, specify specific treatments you might consider (adding these to the graphs, in keeping with Pearl's principles). This also goes for missing data. ...
I don't understand the section on "Controlling for intermediate outcomes".
Pearl then contributes a long and difficult comment. Gelman and Pearl argue over this: "the correct thing to do is to ignore the subgroup identity" - I just don't understand this at all.
 Image via Wikipedia
Image via Wikipedia![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=cc76c124-0ed0-4a9b-a36e-2b9173f9e8ac)



![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=8566b1d9-b35c-40fa-a016-9e77f327bfd4)


![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=3e14185a-e942-40f5-984c-dc210db33ffb)


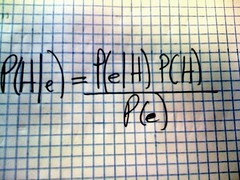
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=7d2eae6c-e832-48c3-a195-bc9c784f14eb)


![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=bba61bb0-8491-4d93-b889-92897233096b)



![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-id=ed1ab458-b039-4c1c-abee-528402e1d414)